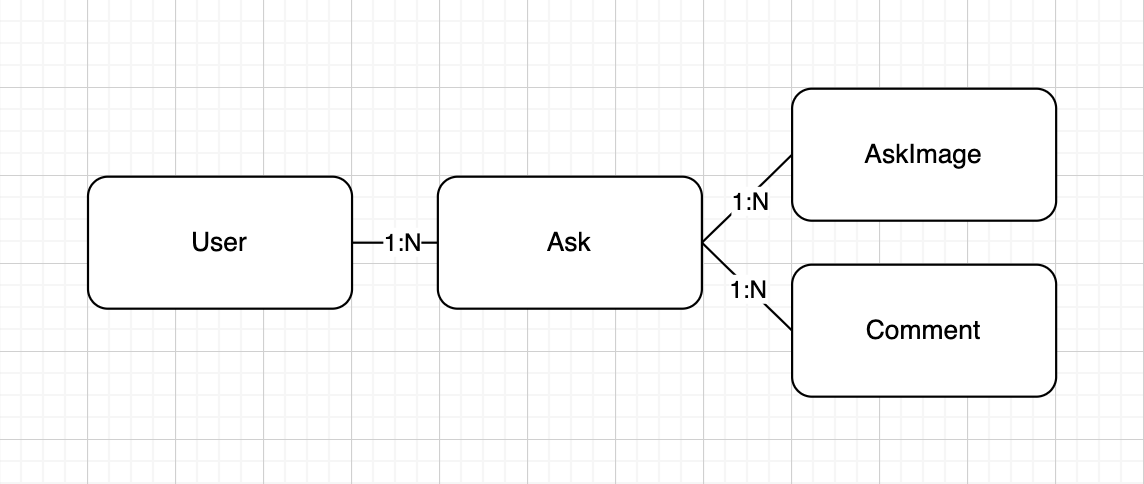
한명의 User가 여러개의 Ask를 작성할 수 있고,
하나의 Ask는 여러개의 이미지와 여러개의 Comment를 가질 수 있다.
Ask를 조회하는 API가 있는데, 해당 API 의 응답 객체는 Ask데이터, User 데이터, Ask의 이미지들(AskImage), Ask의 Comment들을 모두 필요로 한다. 이를 Ask Id를 가지고 조회하는 QueryDsl 코드는 다음과 같다.
Ask ask = queryFactory
.selectFrom(ask)
.where(ask.id.eq(askId))
.fetchOne();하지만 이렇게 하면 Ask의 User, AskImage, Comment들은 모두 Lazy로 설정되어 있기 때문에 이들을 불러오는 쿼리가 발생한다.
즉 Ask select, User select, AskImage select, Comment select의 쿼리들이 발생하는 것이다. 해서 이와 같이 여러 개의 쿼리를 실행하지 않고, 하나의 쿼리로 조인을 사용하여(fetch join) 불러오기 위해 아래와 같이 수정하였다.
Ask result = queryFactory
.select(ask)
.distinct()
.from(ask)
.join(ask.user, user).fetchJoin()
.join(ask.askImages, askImage).fetchJoin()
.join(ask.commentToAsks, commentToAsk).fetchJoin()
.where(ask.id.eq(askId))
.fetchOne();fetch 조인을 사용하여 ask와 연관관계를 가진 엔티티들을 eagar하게 가져오는 것이다.
하지만 위를 실행하면 아래와 같은 에러가 발생한다.
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags
위와 같은 에러는 2개 이상의 OneToMany 연관관계 엔티티, 즉 Collection으로 연관된 엔티티를 끌어오려고 할 때 발생한다.
이에 대한 해결방법은 2가지가 있는데, 하나는 List로 되어있는 연관관계 객체들을 Set으로 바꿔주는 것이고, 다른 하나는 쿼리를 분리하는 것이다.
@Entity
public class Ask {
// ... 생략
@OneToMany(mappedBy = "ask", cascade = ALL)
private Set<AskImage> askImages = new ArrayList<>();
@OneToMany(mappedBy = "ask", cascade = ALL)
private Set<Comment> comments = new ArrayList<>();
}
첫번째 연관 객체들을 Set으로 바꿔주는 것은 옳지 않다. 이는 발생가능한 모든 경우의 수의 행을 가져오는 Cartesian join을 하게 되기 때문이다.
먼저 Ask와 AskImage를 Join하면 AskImage의 개수만큼의 로우가 생성될 것이다. 특정 Ask에 대한 AskImage가 10개라면
1 X 10 = 10이다. 다음으로 Comment가 20개가 달린 Ask라면 또 조인을 하므로 1 X 10 X 20 = 200개의 로우가 생성된다. 이는 성능적인 측면에서 볼 때 너무 많은 연산을 필요로하게 되어 좋지 않다. 해서 나는 AskImage만 fetchJoin을 통해 불러오고, Comment는 따로 불러오는 방식을 선택했다. 그러면 총 2개의 쿼리가 발생한다.
Ask result = queryFactory
.select(ask)
.distinct()
.from(ask)
.join(ask.user, user).fetchJoin()
.join(ask.askImages, askImage).fetchJoin()
.where(ask.id.eq(askId))
.fetchOne();해당 ask 조회 API를 실행하면 아래와 같이 2개의 쿼리가 발생한다.
Hibernate:
select
distinct ask0_.ask_id as ask_id1_0_0_,
user1_.user_id as user_id1_11_1_,
askimages2_.id as id1_1_2_,
ask0_.created_date as created_2_0_0_,
ask0_.is_enable as is_enabl3_0_0_,
ask0_.last_modified_date as last_mod4_0_0_,
ask0_.address as address5_0_0_,
ask0_.bike_profile_id as bike_pro6_0_0_,
ask0_.brand as brand7_0_0_,
ask0_.displacement as displace8_0_0_,
ask0_.gearbox as gearbox9_0_0_,
ask0_.mileage as mileage10_0_0_,
ask0_.model_name as model_n11_0_0_,
ask0_.year as year12_0_0_,
ask0_.description as descrip13_0_0_,
ask0_.garage_id as garage_14_0_0_,
ask0_.is_carried as is_carr15_0_0_,
ask0_.main_category as main_ca16_0_0_,
ask0_.num_of_comment as num_of_17_0_0_,
ask0_.one_garage as one_gar18_0_0_,
ask0_.reservation_id as reserva22_0_0_,
ask0_.sub_category as sub_cat19_0_0_,
ask0_.user_id as user_id23_0_0_,
ask0_.latitude as latitud20_0_0_,
ask0_.longitude as longitu21_0_0_,
user1_.created_date as created_2_11_1_,
user1_.is_enable as is_enabl3_11_1_,
user1_.last_modified_date as last_mod4_11_1_,
user1_.avatar_filename as avatar_f5_11_1_,
user1_.nickname as nickname6_11_1_,
user1_.role as role7_11_1_,
askimages2_.created_date as created_2_1_2_,
askimages2_.is_enable as is_enabl3_1_2_,
askimages2_.last_modified_date as last_mod4_1_2_,
askimages2_.ask_id as ask_id6_1_2_,
askimages2_.filename as filename5_1_2_,
askimages2_.ask_id as ask_id6_1_0__,
askimages2_.id as id1_1_0__
from
ask ask0_
inner join
user user1_
on ask0_.user_id=user1_.user_id
inner join
ask_image askimages2_
on ask0_.ask_id=askimages2_.ask_id
where
ask0_.ask_id=?
Hibernate:
select
commenttoa0_.ask_id as ask_id13_2_0_,
commenttoa0_.comment_to_ask_id as comment_1_2_0_,
commenttoa0_.comment_to_ask_id as comment_1_2_1_,
commenttoa0_.created_date as created_2_2_1_,
commenttoa0_.is_enable as is_enabl3_2_1_,
commenttoa0_.last_modified_date as last_mod4_2_1_,
commenttoa0_.content as content5_2_1_,
commenttoa0_.garage_id as garage_12_2_1_,
commenttoa0_.day as day6_2_1_,
commenttoa0_.from_time as from_tim7_2_1_,
commenttoa0_.month as month8_2_1_,
commenttoa0_.to_time as to_time9_2_1_,
commenttoa0_.year as year10_2_1_,
commenttoa0_.ask_id as ask_id13_2_1_,
commenttoa0_.estimate as estimat11_2_1_
from
comment_to_ask commenttoa0_
where
commenttoa0_.ask_id=?
그런데 위와 같이 join().fetchJoin()을 하는 경우 만약 조인의 대상이 null이라면 (예를 들어서 ask에 image가 없다면)
ask가 존재하더라고 askImage가 존재하지 않으니 ask를 찾을 수 없다. 즉 특정 id로 ask를 select해도 join 문에 의한 조회 데이터가 없으므로 결과가 null이 된다. 하여 아래와 같이 leftJoin을 사용해주자.
Ask result = queryFactory
.select(ask)
.distinct()
.from(ask)
.join(ask.user, user).fetchJoin()
.leftJoin(ask.askImages, askImage).fetchJoin() /* leftJoin 사용 */
.join(ask.commentToAsks, commentToAsk).fetchJoin()
.where(ask.id.eq(askId))
.fetchOne();
이제 쿼리의 빠른 성능을 기대할 수 있을 것 같지만 실제로는 그렇지 않다. 위 쿼리를 실행하면 아래와 같은 에러가 발생한다.
QueryTranslatorImpl : HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
이는 위에서 조인하려는 테이블의 모든 데이터들을 메모리까지 끌고온뒤 메모리에서 페이징을 한다는 것이다. 이는 서버가 죽을 수도 있는 매우 위험한 상황이다. 결국 컬렉션을 패치조인하게되면 페이징을 할 수 없는 것이다.
하여 이를 해결하기 위해서는
1. toOne 관계만 패치조인을 한다.
2. 컬렉션은 지연 로딩으로 처리한다.
3. 다만 지연 로딩 성능을 최적화하기 위해 hibernate.default_batch_fetch_size를 글로벌로 설정하거나 @BatchSize를 적용한다.
위와 같이 컬렉션을 지연로딩으로 한 뒤, batch 사이즈를 지정하면 연관관계가 걸린 엔티티를 touch하면 최대 배치 사이즈만큼 in 절을 사용하여 끌어오게 된다.
'memo > 기록' 카테고리의 다른 글
| jpa 성능 최적화하기2 (update VS delete) (0) | 2023.03.04 |
|---|---|
| AWS LAMBDA with Node.js (0) | 2023.02.22 |
| Querydsl join시 해당하는 ID를 찾을 수 없습니다. (0) | 2022.03.26 |
| User 회원가입 로직 수정하기 (0) | 2022.02.07 |


