데이터 베이스의 3가지 원칙
무결성(data integrity)
데이터가 전송, 저장, 처리되는 과정에서 변경되거나 손상되지 않는 것. 완정성, 정확성, 일관성을 유지해야한다.
안정성(data reliability)
데이터를 보호할 수 있는 방법. 인증/인가되지 않은 사용자로부터 데이터를 보호한다. 고장이 나지 말아야한다.
확정성(data scalability)
데이터 양, 사용자가 늘어날 때 대처가 가능해야한다.
데이터 베이스 종류
relational
1. 데이터를 row와 coloumn으로 이루어진 table 형태의 구조에 저장한다.
2. SQL(Structured Query Language)를 사용하여 데이터를 조회, 저장, 수정한다.
3. MySQL, Oracle, Postgre 등이 이에 해당한다.
key-value
1. key-value 형태로 데이터를 저장하며 key는 unique identifier로도 사용된다.
2. redis가 이에 해당한다.
- cache
- message broker --> pub/sub
- not that scalable --> limitation of the size of RAM
- Dynamo DB
- - partition key - primary
- - sort key - secondary, optional
- - advantage: scalable -> AWS offers, HA, serverless
graph
1. 데이터를 그래프 형태로 저장
2. 각 항목이 node로 이루어져있고, node 간의 관계를 edge를 사용하여 나타냄.
3. sns등 서로 관계가 복잡한 상황에서 주로 사용됨.
4. Neo4j, OrientDB등이 해당
5. 링크드인 - 1촌, 2촌
document
1. 도튜먼트 데이터베이스먼트라고도 한다. 구조가 자유로움.
2. row, column과 같은 구조가 없고, 자유로운 형태로 데이터를 저장한다. (일반적으로 JSON, XML 형태)
3. 데이터베이스 별로 데이터 조작 언어가 따로 존재한다.
4. MongoDB, CassandraDB, Couchbase 등이 이에 해당한다.
5. 블로그 포스트 처럼 사진이 언제 몇개가 들어갈지 모르는 자유로운 형식이 요구될때 주로 사용된다.
row oriented VS column oriented
row oriented :
- 일반적인 MySQL, Oracle과 같은 데이터 베이스
- 대량의 트랜잭션을 지연 없이 처리하기 위해 데이터를 행 단위로 추가하는 구조
- 데이터 검색을 고속화하기 위해 인덱스를 사용한다.
- 레코드 단위로 데이터가 저장되어 있어, 필요 없는 열도 디스크로 부터 로드된다.
column oriented :
- 데이터 분석에 사용되는 DB로 칼럼 단위의 읽고 쓰기에 최적화되어 있음
- 열별로 데이터가 저장되기 때문에 필요한 열만을 로드한다.
- 또한 같은 열에는 유사한 데이터가 반복되기 때문에 매우 작게 압축이 가능하다.
- ex) cassandra, hbase, BigQuery
서비스에 적합한 데이터 베이스 선택법 (CAP Theorem)
CAP Theorem : 분산 시스템에서 일관성, 가용성, 분할 용인 세가지를 모두 만족할 수 없다는 정리. 즉 두가지를 선택하라.
(분산 시스템은 동시에 둘 이상의 node(물리적 또는 가상머신)에 데이터를 저장하는 네트워크)
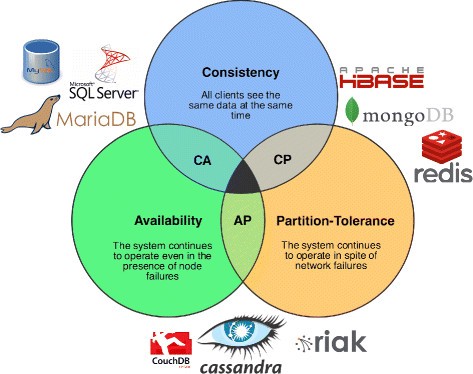
consistency(일관성)
- 어떤 node에 연결되었는지와 무관하게 모든 클라이언트가 동시에 동일 데이터를 볼 수 있음을 의미
- - 이러한 상황이 발생하려면, 데이터가 하나의 node에 기록될 때마다 이 데이터는 쓰기가 '성공'으로 간주되기 전에 시스템의 다른 모든 node로 즉시 전달되거나 복제되어야 한다.
- 데이터베이스 안의 모든 node들이 같은 값을 가지고 있음
- request를 보내면 해당 request가 delay 될 수 있음
- 금융 쪽에서 중요하게 생각함
- 송금 데이터가 데이터베이스 node당 align되지 않으면 해당 데이터를 계속해서 보내는 문제가 발생할 수 있다.
availability(가용성)
- 하나 이상의 node가 작동 중지된 경우에도 데이터를 요청하는 클라이언트가 응답을 받음을 의미 (데이터베이스에 request를 보내면 항상 response를 받음 (consistencty는 response 바로 안옴))
- 분산 시스템의 모든 작업 중인 node는 예외 없이 모든 요청에 대해 유효한 응답을 리턴
- 하지만 해당 response가 가장 최근 데이터라는 것을 보장받을 수 없음
- 접근하는 node에 따라 값이 다르다.
partition-tolerance(분할 용인)
- 파티션이란 분산 시스템 내의 통신 단절, 즉 두 node 간의 연결이 유실되거나 일시적으로 지연된 상태
- 파티션 허용이란 시스템의 노드 간에 다수의 통신 단절에도 불구하고 클러스터가 계속해서 작동해야 함 (node간 소통이 불가능 하더라도 정상적으로 작동함)
NoSQL
NoSQL은 분산 네트워크 애플리케이션에 이상적이다. NoSQL 데이터베이스는 설계상 수평으로 확장 가능하며 분산되어 있다. 하여 여러 개의 상호 연결된 노드로 구성된 확장 네트워크를 통해 빠르게 확장할 수 있다.
CP 데이터 베이스
CP 데이터베이스는 가용성을 희생하면서 일관성과 파티션 허용을 제공. 두 노드 간에 파티션이 발생하면, 시스템은 파티션이 해결될 때까지 일관되지 않은 노드를 종료(즉, 사용 불가능하게)해야 한다. ex) MongoDB
AP 데이터베이스
AP 데이터베이스는 일관성을 희생하면서 가용성과 파티션 허용을 제공. 파티션이 발생하면 모든 노드를 사용할 수 있지만, 파티션의 잘못된 끝에 있는 노드는 다른 데이터보다 이전 버전의 데이터를 리턴할 수 있다. (파티션이 해결되면, AP 데이터베이스는 일반적으로 시스템의 모든 불일치를 복구하기 위해 노드를 재동기화.) ex) Cassandra (Cassandra에는 마스터 노드가 없다)
CA 데이터베이스
CA 데이터베이스는 모든 노드에서 일관성과 가용성을 제공. 그러나 시스템에 있는 두 노드 사이에 파티션이 있는 경우 이를 수행할 수 없으므로, 결함 허용을 제공할 수 없다. (분산 시스템에서는 파티션을 피할 수 없다는 이유 때문에, CA 분산 데이터베이스를 이론적으로 논의할 수 있지만, 실제적인 목적으로 CA 분산 데이터베이스는 존재할 수 없다고 한다 )
RDBMS VS NoSQL
| RDBMS | NoSQL | |
| 데이터 모델링 | -스키마에 맞춰 저장하기 때문에 데이터 정합성 보장 -관계를 맺고있는 데이터가 자주 변경되는 경우 용이 |
- 자유롭게 데이터를 관리할 - 데이터 구조를 정확히 알 수 없는 경우 용이 - 데이터가 변경/확장될 수 있는 경우 용이 |
| 확장 | Scale Up | Scale Out |
| 쿼리 언러 | SQL | NoSQL마다 문법 상이 |
| 데이터 일관성 | 강함 | 일관성 보장에 시간이 걸릴 수 있음 |
| 유연성 | 약함 | 강함 |
* scale up : 서버의 하드웨어를 더 높은 사양으로 올리는 것. (수직적 확장)
* scale out : 장비를 추가함. 예로 하나였던 데이터베이스 서버를 2개로 확장함 (수평적 확장)
참고:
원티드 벡엔드 2월 챌린지 강의자료
https://sulmasulma.github.io/data/2020/04/18/row-and-column-oriented-database.html
https://jasonkang14.github.io/database/cassandra-db
'MySQL' 카테고리의 다른 글
| wanted 백엔드 첼린지 2-1 MySQL 기본개념 (0) | 2023.02.20 |
|---|---|
| wanted 백엔드 첼린지 1-2 Big Tech가 MySQL을 사용하는 이유 (0) | 2023.02.12 |

